rabbitmq是一款实现amqp 协议的软件,我们在通过php 使用rabbitmq 的时候有两种方式(类似php 使用redis,一种是通过c扩展的方式,一种是纯php实现的lib 包。其实还有异步引擎,swoole是通过c扩展的方式,workman 是通过php 实现的lib包),一种是安装php 的amqp扩展 http://docs.php.net/manual/da/book.amqp.php,一种是市面上比较流行的库https://github.com/php-amqplib/php-amqplib, 识货内部就是通过简单使用这个库来进行和rabbitmq的交互。
不同的角色
关于rabbitmq 的理论知识,https://www.cnblogs.com/wutianqi/p/10043011.html, 这篇文章讲解的很清楚。
生产者 : 也是通过channel, 去 declare 一个 队列 ,然后发送消息(为什么要使用channel, 因为tcp 连接断开重建很浪费资源)。如果中间没走exchange 的 话,就不需要 routing key 了 。很多人经常把routing key 和 队列名称写一样,因为可能这个消息当初考虑的时候就是专门给这个队列queue 使用的。但其实 routing key 和 queue 可以不一样的,消费者在定义自己的队列便于接受 exchange 投递过来的消息,routing key 就相当于一把钥匙,可以打开这个队列的门。
上面关于生产者的描述并不准确,上面的过程大概就是单个脚本发送消息的过程,是一种翻译。准确的生产者只做一件事,就是发送消息。首先获取connection, 再通过connection 去获取channel (如果是消费者的channel ,我们在rabbitmq的管理界面还能获取到这个消费者的详细信息)。然后通过channel 去 publish 消息,就结束了。其中关于exchange 的 declare ,是重复的操作,我们可以提取出来,而不分给生产者发送消息这个行为 ,因为publish 的时候我们是不需要exchange 的declare 的,我们完全可以手动在web 上新建exchange, 然后publish的时候填入 exchange 的名称。同理 queue的declare 也是如此。所以我们在生产者消费者的同时,我们可以一方去declare 就好了。
channel 的publish 方法第二个参数是key ,当我们是 简单或者工作或者 fanout 模式的时候,这个key 就是 queue的名称。一定要注意如果这个key 是空的,或者不存在,我们的消息就会丢弃,因为没地方存储。
说到这里,就需要注意一下我之前的一个误区,开了生产者,然后启动消费者,消费者拿不到消息,消息为啥丢失了吗?我的理解中,不应该消息积存了,后来消费者启动了,开始消费吗?其实主要是exchange 不能存消息的,当我们启动消费者的时候,经常会启动一个队列,如果这个队列以前不存在,exchange拿着routing key 匹配不到 队列,就会把这个消息丢失。
消费者:和上面的生产者对应
同理,消息者其实也是获取到一个connection, connection 获取到channel ,我们就可以去消费消息了 (go 消费消息好像只能用协程的方式)。channel consume 的时候需要一个 queue 的名称,其他什么都不需要。但我们需要把这个queue 绑定到对应的exchange 上,注意了!!!因为识货一直用的routing key 都是字符串,所以不涉及匹配模式,所以我们很容易把生产者的routing key 和 消费者的routing key 当做一个,其实在topic 模式下 queue的 routingkey 需要是正则表达式,比如 #.coupon.#, 生产者 1.coupon.2 就能被这个消费者消费到,不要搞反了。 #可以接收到所有的消息。
总结:
所以我觉得,对于生产者,可以定义exchange ,但是queue 这些没必要,因为我们发送消息的时候只要exchange ,和 routing key 。
对于消费者,可以定义exchange (如果生产者没定义)。需要定义queue,因为consume 的时候需要,需要queue bind exchange 利用 binding key。
消息代理: broker ,kafka 也有这个玩意,但kafka 的broker 上面有分区,可以存储消息 (rabbitmq 就是一种消息代理)
虚拟主机:vhost, 识货到现在都没用 (可以利用不同域名区分生产和开发环境,识货直接用的不同的ip)
交换机:exchange,识货到现在只用一个exchange 就是 amp.topic
绑定: binding, 把队列queue 和 exchange 绑定起来
路由键: routing key, 生产者把消息推送到 exchange 上
队列:queue
连接: connection
通道: channel
消费者: consumer
不同的工作模式
一共有5中
没有exchange 的有simple 和 work 模式,simple p -> queue->c, 这样
work p-> queue ->(c1, c2)
exchange 又分多种工作模式,比如topic, direct, fanout. (这三种相较于上面的 work 模式就是不同的队列消费的是同样的消息)。工作中其实我们无意的都在使用work 模式,因为会启动多个消费者。之所以多个消费者消费不同的消息,是因为我们的生产者的routingkey 是不一样的,即使我们消费者的binding key 是一样的。
识货用的都是direct (虽然 amq.topic 这个交换机的类型是topic ),但是绑定 exchange 的queue 的 bindingkey 一直类似 a.b.c 这样,所以其实就是direct。这种有个坏处就是某个queue 需要另一个routing key的数据,我们不得不在这个queue上绑定一个新的bindingkey 对应这个新的routing key, topic 模式就是为了解决这个问题出现的 , bindingkey 对于 routing key 的模糊匹配。那什么是fanout呢,fanout就是不要routing key 的 direct, 直接推所有绑定到 exchange的 queue。
写代码的时候应该注意的几个属性
交换机的属性:(识货就用一个交换机 amp.topic 所以这些都没用用过)
name:
durable: 持久化,消息代理重启后,交换机是否还存在。交换机有两个状态,持久(durable)、暂存(transient)。持久化的交换机会在消息代理重启后依旧存在,而暂存的交换机则不会。
auto-delete: 当所有与之绑定的消息队列都完成了对此交换机的使用后,删掉它。
arguments: 依赖代理本身
队列属性:
name:
durable: 消息代理重启后,队列是否还在。
exclusive: 只被一个连接使用,连接关闭后,将立即删除队列。(这个排他性也很坑爹,如果设置了,经常别的连接不能用)
auto-delete: 当所有的消费者都退订队列后将自动删除该队列 .(如果设置false, 经常就是消费者没了,队列也就没了)
消息属性:(识货这边从来没设置过,照样跑)
Content type(内容类型)
Content encoding(内容编码)
Routing key(路由键)
Delivery mode (persistent or not)
Delivery mode (persistent or not)
投递模式(持久化 或 非持久化)Message priority(消息优先权)
Message publishing timestamp(消息发布的时间戳)
Expiration period(消息有效期)
Publisher application id(发布应用的ID)
消息确认:
消息确认开启后,如果我们没有确认消息,消息会是 unack 状态,当消费者挂掉后,几秒中unack的消息会重置成total 未消费状态 (一定要注意)
未确认的东西。识货的消息从来没有设置持久化状态,但是mq 挂掉了之后消息还能找回来。
(消息能够以持久化的方式发布,AMQP代理会将此消息存储在磁盘上。如果服务器重启,系统会确认收到的持久化消息未丢失。简单地将消息发送给一个持久化的交换机或者路由给一个持久化的队列,并不会使得此消息具有持久化性质:它完全取决与消息本身的持久模式(persistence mode)。将消息以持久化方式发布时,会对性能造成一定的影响(就像数据库操作一样,健壮性的存在必定造成一些性能牺牲)。)
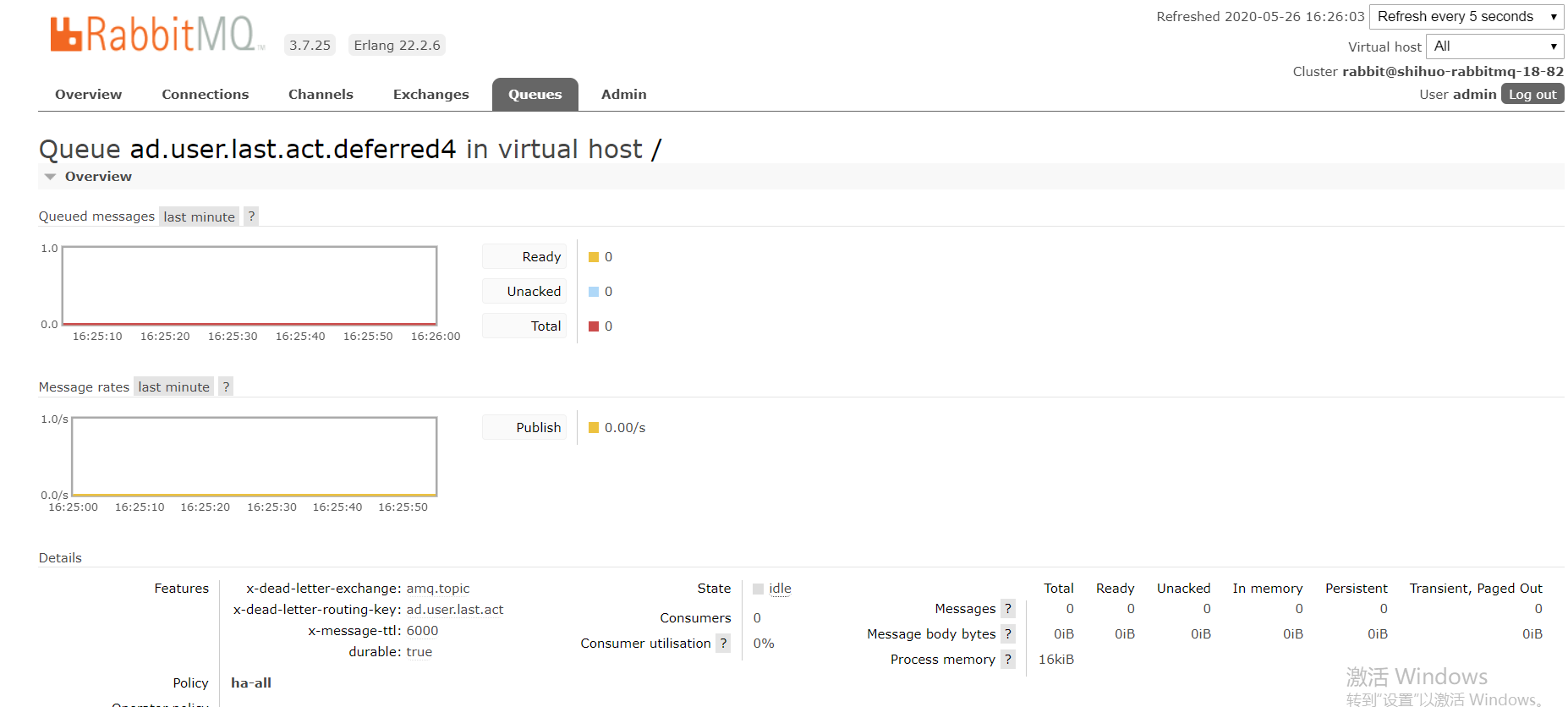
要善于利用rabbitmq 的管理界面,注意detail 那块,这是我们使用死信队列造成延迟队列。

下面的consumer 可以知道绑定的消费者
下面的binding 就是通过routingkey 绑定的信息
延迟队列
延迟队列的应用场景:比如订单三十分钟内付款有效。
实现方式:https://www.cnblogs.com/-mrl/p/11113989.html
rabbitmq 延迟队列的实现方式:通过消息过期,转发到死信交换机中。消息过期有两种方式,一种是消息自己的存活时间到达还没有消费,一种是队列的时间到达但其中的消息没有被消费,这两种情况消息都会被投递到死信队列中。
区别:第一种我们可以单独对每个消息设置存活时间,不需要为了每个不同的时间建立不同的队列,比如a消息三十分钟过期,b消息40分钟过期,我们都投递到一个没有消费者的队列中,消息到期了自动转发到死信队列中。
补充:
https://jaskey.github.io/blog/2018/08/15/rabbitmq-delay-queue/
上面的做法好像缺点更大,容易造成队列堵塞,所以还是弄成不同时间级别的队列吧。
识货从来没有nack 这种操作,只有ack。
nack 不等同于超时,超时是还没有应答,属于 unack,nack 是应答错误 ,是程序执行完了。(nack 如果需要重回队列,需要设置 repeat true,消息回到队列头部重新开始消费,我们需要注意消费消息的幂等性, 还要小心造成死循环。如果没有设置repeat true ,消息会被丢弃)
unack 的消息在这个消费者挂掉重启的时候会重新被消费 (或者可以被自己的兄弟消费者消费掉)
好久没用rabbitmq ,认知又有点生疏,以识货代码为例
produce
1 | $routingKey = $queName = 'apps_kb_other'; |
consumer
1 | $routingKey = 'apps_kb_other'; |
我们日常发送消息,在网上抄的代码,都是
1.get conn
2.conn open channel
3.channel declare queue (注意这一步是可以省略的,当queue 已经存在的时候 。我们重复定义queue 不会报错,但是我们定义了重复queue ,给的属性,比如 queue 中消息的ttl 不一样,会报错的。)
4.channel 发送消息,此时只需要传入一个 queue 的名称即可,notice !!! 如果我们没有用到exchange, 我们千万不要传,否则 会出现奇怪的现象。
5.发送消息时候的两个属性,mandatory immediate, 概括来说,mandatory标志告诉服务器至少将该消息route到一个队列中,否则将消息返还给生产者;immediate标志告诉服务器如果该消息关联的queue上有消费者,则马上将消息投递给它,如果所有queue都没有消费者,直接把消息返还给生产者,不用将消息入队列等待消费者了 来源
1 | // go 发送mq 的代码 |

