收集一些总是考的面试题
Web
1 | 怎么会导致跨域,为什么会出现跨域 |
1 | get post 区别 |
1 | 正则 |
1 | http请求过程 |
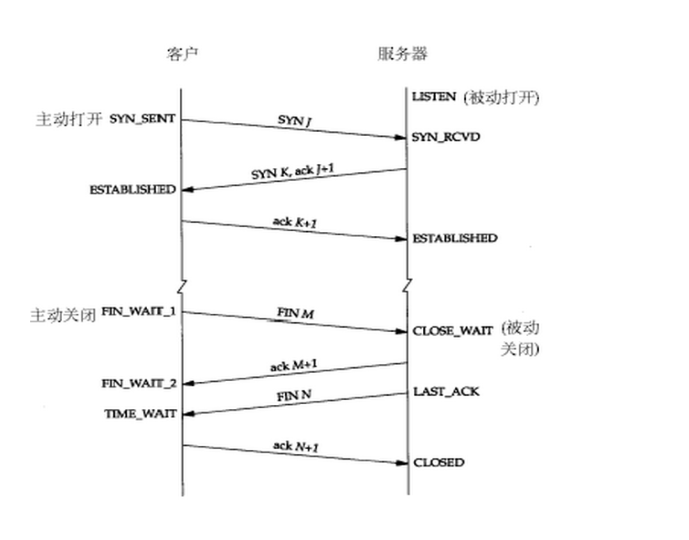
1 | 常用的http状态码 |
1 | https 和 http的区别 |
1 | 什么是socket编程 |
1 | OAuth(Open Authorization) 协议为用户资源的授权提供了一个安全的、开放而又简易的标准,第三方无需使用用户的用户名与密码,就可以申请获得该用户资源的授权。 |
1 | csrf 攻击 |
PHP
1 | PHP 位运算符 |
1 | 字符串比较 |
1 | setcookie(xxx); |
1 | 常用string ,arr 函数 |
1 | array_merge 和 + 的区别 |
1 | php7新特性 |
1 | php7为什么相较于php5性能有很大提升? |
1 | php垃圾回收机制 |
1 | 如何解决php内存溢出问题(phpexcel中经常出现,第二个很管用) |
1 | $z = 0.58; |
答案是 57,所有语言对于小数的存取都是不精确的, 0.58其实是0.57999999,而且intval() 总是从遇到第一个不是数字开始截取,导致了0.57,比较通用的方法是转成别用intval, 或者用数学函数,bcmath扩展计算
1 | cookie 和 session 的 区别 |
1 | spl_autoload_register和 _autoload 的区别 |
1 | 判断一个日期是否合法 |
1 | 单引号,双引号区别 |
1 | include require 区别 |
1 | 中文截取字符串 |
1 | 平时开发用的设计模式 |
1 | 常用的魔术方法 |
1 | php 错误信息控制 |
1 | trait Singleton {} |
1 | 抽象类只能继承, extend ,接口可以实现多个,比如我想我这个类拥有foreach, 之类的功能, implement |
1 | static ,延迟静态绑定, |
1 | 防止sql 注入 |
1 | 红包,我能想到比较简单的方法 |
1 | 同步,异步区别 阻塞非阻塞区别 |
1 | ab 测试 |
1 | yield 感觉就类似分页,有效减少内存的消耗(大数据量一次性读入内存吃不消),注意yield 的使用和数组还是有区别的. |
1 | 自带的接口 |
1 | php 进程间通信的方式 |
1 | 几个预定义接口 spl标准类库 |
1 | php 多进程写入同一个文件 |
Laravel
1 | laravel 调优 |
1 | laravel 生命周期 |
1 | loc ,facade, contract, 服务提供者是什么 |
1 | laravel 和 其他框架的区别 |
Mysql
1 | mysql 性能优化 |
1 | mysql 乐观锁,悲观锁,共享锁,排它锁,行锁,表锁 |
1 | mysql 的隔离级别 |
1 | int(1) 和 int(11)的区别 |
1 | varchar 和 char 区别 (括号中是字符数) |
1 | hash索引和b+索引的区别 |
1 | innodb 和 myisam 存储引擎的区别 |
1 | 什么样的字段适合建立索引 (索引建立的标准) |
1 | 常见的索引 |
1 | mysql_fetch_row, mysql_fetch_assoc, mysql_fetch_array 区别 |
1 | limit, left join ,order by ,group by, where , select , from ,having |
Nginx

1 | 404 最长匹配原则,但是只能匹配到 a |
1 | nginx 负载均衡(属于反向代理)upstream prox_pass关键字 |
Redis
1 | redis 和 memecached的区别 |
1 | redis 怎么持久化 |
1 | redis 的常用数据类型 |
1 | redis 的使用场景 |
1 |
Linux
1 | linux 常用命令 |
1 | git rebase 变基,比如把当前分支的分叉点移动到主分支最新节点,为的就是log日志中不产生分支 |
1 | awk 的使用 |
算法
1 | 4种排序 |
1 | 查找 (注意查找的算法都是在排好序的基础上) |
1 | 1000000个数字的整数, 大小是0 到 999999, 找出其中重复的数字. |
1 | 广度优先算法 |
1 | 567123, 怎么找出1 |
项目
1 | 订单系统 |
1 | 100件商品高并发,先到先得 |
1 | 30w 的ip地址,类似如下 |
1 | .请设计一个投票系统,满足如下要求 |
1 | .用php写一个函数,获取一个文本文件最后$n行内容,要求尽可能效率更高,并可以跨平台使用 |
1 | 有两个文本文件 A.txt B.txt |

