事情是这样的:今天在看一个课程的时候,说redis 是非阻塞的,但redis 是单进程的,而且之前我给redis备份数据的时候,确实客户端的响应会比较慢, 感觉这应该属于阻塞,于是查了一下php 的非阻塞模式
https://www.awaimai.com/660.html
1 | $cmh = curl_multi_init(); |
比较有用的就是上面这段代码,说是非阻塞的http请求,我改了请求地址,对应我用swoole写的一个http sever, 故意在服务端sleep, 然后客户端直接打印出了时间,并没有等服务端跑完。此时感觉这和异步的结果很类似,但相比较于异步,我感觉这个区别就是没有回调,脚本直接结束了,进程也结束了,不会管最后返回的内容是啥。试着查询pid, 果然此时已经查询不到了。但是异步的话,进程不会结束,常驻内存,有线程或者进程通知主进程最后的执行结果。 又因为在结果层面上,非阻塞和异步的效果是一致的,都跳过了这段代码的执行,所以导致大家分不清楚。
之前看到swoole文档上说array 函数是非阻塞,但我感觉array_map 这种循环(注意funciton 中不要写阻塞函数,比如sleep, 但在数据量大的时候感觉也会停在那好一会)而且非阻塞或者异步情况,都是返回结果毫无意义的,这些单个函数的话,我们肯定要判断返回值,所以不能说是非阻塞或者异步的吧,只能对那些io请求说是阻塞和非阻塞,同步和异步。
还是回到最上面那段代码,当我netstat -antp|grep 56735, 发现tcp连接是close_wait,这个好久之前在一篇文章中看到过(大愚talk)
我们都知道tcp建立连接需要三次握手4次挥手,这张图片我应该无数次看到了
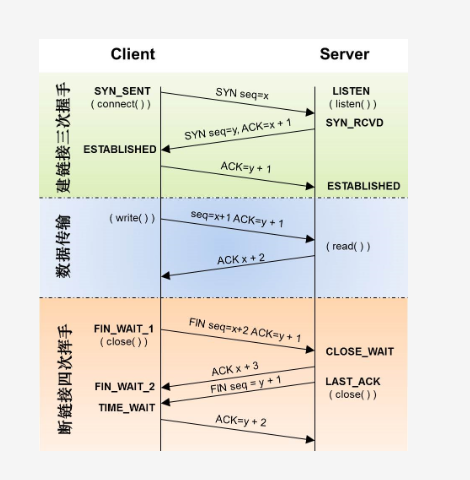
之前就很好我有时候netstat -antp|grep 56735 ,可以看到一条正向连接, 56735 - 某个端口,某个时候还能看到一条正向一条反向连接,56735-某个端口,某个端口-56735, 为什么 是两条呢,为什么有时候看到一条,有时候看到两条呢,我后面又试了一下 curl 127.0.0.1:56735, 结果发现这时候出现了两条连接,而且两条连接的进程还不一样,一条是curl, 一条是 php ,所以的理解就是两条,之所以平时我只能看到一条是因为另一条的执行进程是浏览器,不在我们服务器上,所以查看不到。(还有什么可以证明是两条tcp连接,我们客户端可以主动断开,服务端也可以,所以我们服务端会出现上图的time_wait状态)
那为什么我们的服务器上会出现大量的time_wait, 不应该只有client 上才会出现吗,因为那张图片上的client 和 server 并不是我们实际工作中的客户端服务端,当我们服务端发送tcp连接的时候,我们服务端就相当于图中的client,之所以会出现close_wait, 是因为我们另一端client发送请求者也就是上面那段代码直接结束了,主动关闭了连接,然后我们服务端还没有跑完,只收到了client的 fin,回复了ack,并没有主动发送fin,断开服务端这边,上述也是模拟tcp close_wait的例子(被连接者也就是foreign address 主动关闭)。当出现大量的close_wait, 会消耗很多服务器资源。有什么办法能销毁这个close_wait 嘛,进程结束,在上面例子上也就是我们服务端进程结束,或者重启,这个tcp连接会主动释放,这也是大愚talk中解决的问题:“mysql 主动关闭连接,我们没有释放连接”。为什么以前php-fpm 模式不会出现,因为以前一个请求结束,所有资源都释放(咋释放的?我记得fast-cgi 可以配置某个进程在接受大量的请求之后自动重启,为了防止内存溢出,可是现在好像每次都会重启。可以在lnmp下测试,mysql主动关闭,看这个tcp连接是否消失,如果直接消失了,说明立刻就重启了吧),现在swoole常驻内存模式,进程不结束,资源得不到释放。
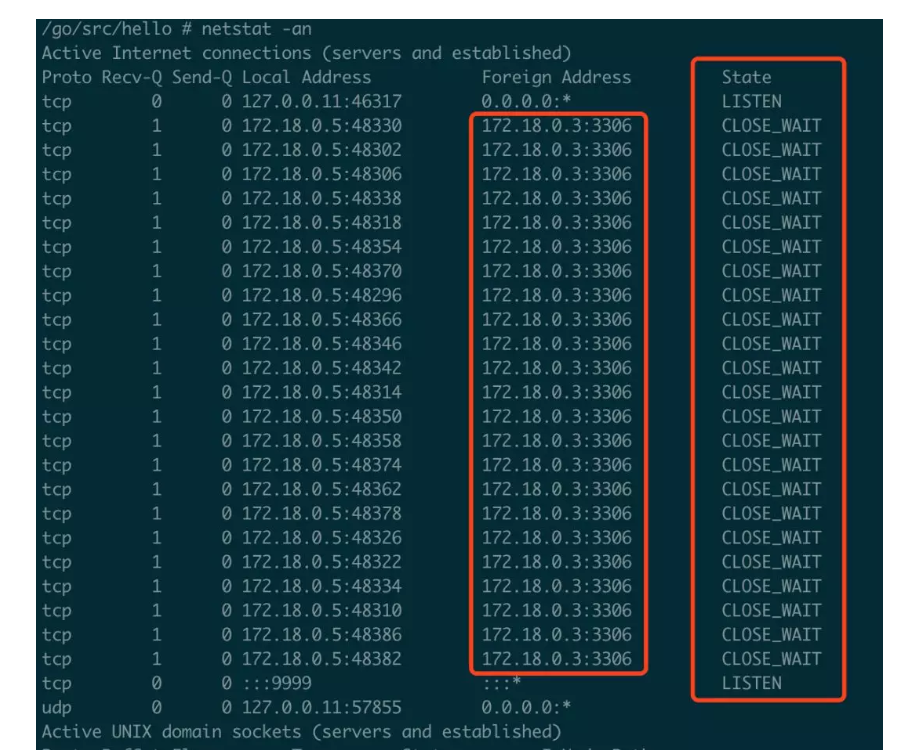
上图中还能发现连接mysql的端口3306确定外,这边端口这么多种多样,明明只是一个脚本的连接呀,其实你可以在php-fpm模式下实验,如果照之前的想法,那php和mysql的连接就应该是端口80 到 3306,可实验结果不是,为啥?因为进程号代表我们这个程序,但是一个程序连接别的端口可以自己生成多个,那个80 和 3306 相当于我们listen 的 socket, 但是我们自己又可以生成多个socket 去连接别人的listen。
还记得swoole中为啥要进程池吗,想想一下,如果一条mysql连接(长连接,我们curl 的连接是短连接,所以李哥经常说的用php维持一个长连接指的应该是这个,长时间不断,可以复用,但这个和websocket不一样哦,websocket 可以服务端主动推送,长连接不可以)长时间没操作,超过wait_timeout (非shell情况下,shell情况下依据 interactive_wait_timeout), mysql主动断开连接,此时即使我们这边tcp 连接还在,mysql给我们的tcp连接不在,那也没法返回数据了(就是那种mysql挂了,我们因为用了单例模式,连接还在,不能重新连接),所以我们需要ping 一下,当能收到反馈,再用。一般连接复用(比如单例模式)都应该这样,但我们很少出现mysql这么主动断开的情况,所以也不用ping, 除此之外,我们还可以利用进程池解决上述问题,从中选择没有被close_wait 的连接(怎么关闭close_wait,我的想法是对于那些ping ,没有返回的连接,我们直接close, 而不能通过异常,除非是那种数据不能传输的异常,我们可以close,否则还可能我们查询有问题导致异常,但是这条连接本身没问题)
还记得itbasic上的连接经常出现这种问题吗,之前是可能是因为一个死循环,导致数据库挂了,所以连接就挂了(我回去试一下,算上上面一共连个测试点)(抓包分析下redis命令)
关于长连接和短连接
现在http1.1 默认长连接,长连接和短连接是啥,长连接指的是tcp连接可以复用,剩下的http请求都走之前建立的tcp连接,怎么证明. netstat 一下,发现线上连接都是establish,然后再次请求,还是一样,过了一会,全部消除(和ws不一样,虽然都是establish,但是ws可以主动推送,而且维持时间更长)
当我们用curl请求的时候,就是短连接,请求完直接time_wait, 2个钟头后直接结束,所以大量的time_wait 并没有啥事(还有fin_wait 2 如果没有收到服务端的fin, 过一段时间也会直接消失)
(为什么time_wait 之后2个钟头就结束,这1个钟头是数据包在网络上存活的最长时间, 为的是发过去的确认包对方没有收到,又发新的fin包过来,对方最晚发送的新的fin包是我们这个确认包在网络上的存活时间也就是一个钟头,加上新fin包的存活时间一个钟头,也就是两个钟头,当然在这个第一个fin和最后一个fin包之间,可以发送无数的fin确认包)
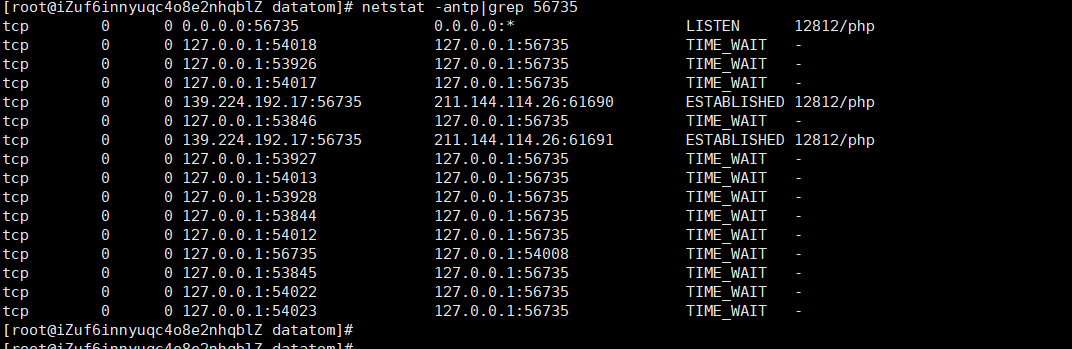
上图中的time_wait 就是我用php自身创造的请求,establish 是我们的浏览器http请求,怎么判断的,看ip知道孩子,211.144.144.26是我们当前ip,127.0.0.1 是本机
(之前一直以为因为websocket 导致request请求建立的连接也是establish,然后手动close,现在看来是错误的,它本身就是长连接,可以测试一下过一会他是否主动断开,感觉肯定不需要用户手动close)
1 | swoole版本是4.3.5 |
后面都是以前写的垃圾,没有整理、
首先来介绍下有关网络的相关知识吧,iso,国际标准化组织 制定了 osi七层模型,但这个模型在现实生活中并没有使用,使用的是基于7层模型之上的tcp/ip 4层模型



二者区别
上三层是给用户提供服务的,下四层是数据传输用的(数据不传输的下4层不用了,但上3层还是要用的)
既然是数据传输,那必然就有单位,每一层传输的单位是不一样的,osi7层模型上都有标识,最底层的物理层单位比特,代表的就是0或者1这个单位
这些层在水平上的传输,然我们以为他们就是直接想通的,其实他们是从高到低,再从低到高这样传输的。
各个层的作用,感觉了解一些就可以了
1.物理层:底层传输
2.数据链路层:通过不同的mac地址,通过交换机进行传输,此时还没有ip地址,so交换机肯定是不认识ip地址的啦
3.网络层:ip地址,路由器,通过对不同路由器的选择,去寻找不同的主机服务器
4.传输层:tcp udp的定义,tcp安全可靠没有udp快,但udp不可靠,还有来确定端口号(端口号的理解,这封信送给你家,只有署名了,才知道给你家的某个人,外来的请求,只有确定了端口号,你才知道这个请求是给哪个服务的)
5.会话层:这个文件是直接存储呢,还是要进行网络传输呢
6.表示层:数据的表现形式,加密啊,我们window上文件的高级属性也能加密,但是秘钥保存在本机应该是c盘,一旦重装系统,秘钥丢失,那这个文件也可能就打不开了
7.应用层:用户接口
线面这张图能表名上面的作用

a: 你在吗?
b:我在,你还在吗?
a:我还在,我穿输了
其实这个应答应该是没完没了的,但3次之后准确率就比较高了
下面介绍一下ip有关内容
ipv4结构如上所示,图中可以看出选项有的有,有的没有,所以结构不唯一,需要检测,没有ipv6固定,速度快
可以看出32次方,一共2的32次方个
默认 0.0.0.0 到255.255.255.255
其实如下,很多不给用的,就a b c类能用,其中还包括一些私有的,只有局域网内网才能用
127这个网段只有一个也就是自己
127.0.0.1
上面的ip地址第一个字段代表不同的网段,不同的网段需要通信,要用路由器
a类网段,拥有的主机数是 2的24次方
b类:前两个数代表不同网段,后面两个数代表不同的主机
c类:前三个数代表不同网段,后面1个数代表不同的主机
同一个网段交换只要交换机就可以了
这个网段是怎么决定的呢,是有子网掩码决定的,子网掩码的255代表网段,0代表主机,ip地址都是配合子网掩码使用的,没写是因为有默认
最大的主机数(-2 一个是网络地址,一个是广播地址)
私有ip不要钱,有效的保护公网ip不够用
缺点:不能访问公网ip,公网ip也不能访问私网ip(公网ip是互联网上唯一的门牌号)

网络的计算:ip地址和子网掩码和,因为子网掩码前面全是1,所以网络地址网段和ip地址一样,后面子网掩码全是0,所以网络地址主机是0
广播地址怎么算呢,子网掩码有多少位是0,就换算多少位1,前面网段不变,这样就是广播地址


udp 比tcp简单,所以udp比tcp块
常见端口号
http 80 https 443
mysql 3306
ssh 2222
redis 忘记了
smtp 25(简单邮件传输协议)
不管是window还是linux都禁止了23端口,因为telnet是明文传输,截获了都不用破解
DNS 进行域名解析
虽然我们的端口分tcp和udp,但是系统怕我们弄混淆了,不管tcp的20 21还是udp的20 21都是分配给ftp使用的
DNS(尽然既可以接受tcp协议也可以接受udp协议)

listening 表示本机正在监听
establish 表示建立连接
udp的状态为空,因为udp不管你在不在,都会给你发送数据
(我想攻击一个游戏服务器,我把我所有的外部连接都关掉,然后登陆游戏,然后netstat 查看外部连接,就能知道对方的ip地址了)
关于DNS的知识
ip地址太难记,没有域名形象,so 产生了DNS
window的host文件是做静态ip和域名对应,优先于DNS匹配,so我们经常本地测试绑定虚拟域名的时候都是这么干的
早期就是通过host文件这么解析的,坏处
dns原理

域名解析原来是从后往前的,··顶级域名在后面


原先有个.me 的国家域名可以申请
这个是全球唯一的(比如www.sina.com 和www.sina.cn就是两个域名,为了防止别人误入错误的地址,大公司会把那些顶级域名都注册了,以免坏人的误导)
三级+二级+顶级+组成完整的域名
根域名管理一级域名,一级域名管理二级域名,二级域名管理三级域名,这种层层管理
dns一般劫持被误导非常难,你只要确保imooc.com 这个二级域名是否是这个网站的,就能确保是否是钓鱼网站(确保二级域和顶级域一致)
域名解析过程
主要分为开始的递归查询和后面的迭代查询
默认本地域名服务器解析的域名保留3天
(这种分级的更有利管理)

迭代查询允许返回一个最优的值,比如顶级域名不知道,让本地域名服务器去找cn解析
全球所有的域名服务器都知道13台根域名服务器
但是递归查询不可以,递归要么返回一个准确值,要么返回错误
所以,递归查询一般用作客户机和本地域名服务器之间进行查找(注意这个查找虽然图中只是一台,其实会有很多台)
而迭代查询一般用在根dns和cn,com这些之间进行查找

